Probability#
I was promised a book on data analysis and the first chapter is about probability, why?
The concept of probability, and how to work with it, is a pre-requisite to perform data analysis. Probabilities are one of the mathematical tools that will allow us to make quantitative statements about data.
Randomness#
Probability and randomness come as very closed ideas. Let’s begin by trying to understand what we mean by randomness.
The classical example for randomness comes from tossing a coin where the outcome is head or tail. Because it is a classical system, its outcome can in principle be predicted by evaluating the equations of motion. So how can the aspect of randomness arise from a, at least in principle, deterministic system? The issue is that in order to predict precisely the evolution of a physical system it would be necessary to “prepare” it in a configuration with infinitely precise initial conditions, which is in practice not possible. On this case, probability comes in as a convenient tool to predict the outcome of the experiment (head/tail).
A different situation is encountered in quantum mechanics when we study the physics at the atomic and sub-atomic scale. Here the governing laws are “intrinsically” probabilistic.
Probability#
There are several definitions of probability. We will start from the axiomatic definition and then introduce the frequency interpretation. After having defined the conditional probability we will consider the subjective interpretation arising from the Bayes theorem. Later in the course we will address the implications on statistical inference coming from the frequentists/Bayesian interpretation of probability.
Axiomatic definition#
We beging from the axiomatic definition of probability (also known as the Kolmogorov axioms). Let \(S\) be the set of possible outcomes of an experiment. For every possible outcome \(E\subseteq S\) the probability \(p(E)\) fulfills the following axioms:
\(P(S) = 1\)
\(P(E) \ge 0\)
\(P(\cup E_i) = \sum P(E_i)\) for any set of disjoint \(E_i \subset S \) and \(E_j \subset S\) (i.e. when \(E_i\) and \(E_j\) are mutually exclusive)
It follows immediately that:
\(P(E) = 1-P(E^*)\) where \(S = E \cup E^*\) and \(E\) and \(E^*\) are disjoint
\(P(E) \le 1\)
\(P(\emptyset) = 0\) where \(\emptyset\) is the null set
Any P fulfilling these axioms can be called probability.
Probability as frequency limit#
The most popular definition of probability is based on the limit of relative frequencies. In particle physics, where we scatter particles several times and we count how often a certain process occurs, this definition seems particulary appealing.
Assume we conduct an experiment which has a certain number of descrete outcomes (events).
Suppose we prepare N identical
experiments (or identically repeat the experiment N times)
and find that the outcome \(E_i\) occurs \(N_i\) times. We
assign the probability P\((E_i)\) to the outcome \(E_i\), as defined by its
relative frequency of occurrence:
\(P(E_i)=\lim_{N\rightarrow \infty} \frac{N_i}{N}.\)
It’s easy to verify that this definition satisfies the axioms given above. This definition is also called the objective posterior probability, because the probability is defined a posteriori, i.e. after the outcomes of the experiment are known.
The “frequency limit” approach is very useful in practice, however:
the limit does not exist in a strict mathematical sense. There is no deterministic rule linking the outcome of experiment \(j\) with the outcome of experiment \(j+1\).
how do we prepare \(N\) identical experiments? Is it sufficient if they are very similar? (e.g. back to the coin toss: at each toss the coin has some abrasion and the \((j+1)^{th}\) toss is not identical to the \(j^{th}\)).
nobody can conduct infinitely many experiments. When does the series converge to the limit?
for some problems this definition is meaningless: what is the probability that tomorrow will rain ? it’s a single experiment; what is the probability that Nature is supersymmetric ? it’s either susy or not.
Conditional probability#
Let A and B be two different events. The probability for A to happen is \(P(A)\) and correspondingly \(P(B)\) is the probability for B to happen. The probability that either A or B happens is given by:
where \(P(A\, \cap \, B)\) denotes the probability that A and B occur together. If A and B are mutually exclusive, then \(P(A\, \cap \, B)=0\).
Let \(P(A|B)\) be the conditional probability that event A occurs, given that event B has already occured. Then \(P(A\, \cap \, B)= P(A|B) \cdot P(B)\): the probability that A and B happen is the probability that A happens given B, multiplied by the probability that B happens. The conditional probability \(P(A|B)\) can be written as:
If the two events are independent, then \(P(A|B)=P(A)\), i.e. the occurrence of A does not depend on B, and so \(P(A\, \cap\, B)=P(A)\cdot P(B)\). In plain english, the occurrence of B does not influence the occurrence of A.
Example:
Suppose you draw a card from a deck of 52 cards and it’s red. What is the probability that it is also a diamond ?
\(\mbox{P(diamond|red)=}\frac{\mbox{P(diamond}\, \cap\, \mbox{red)}}{\mbox{P(red)}}\)
\(\mbox{P(diamond}\, \cap\, \mbox{red)}\) = number of red diamonds divided by the total number of cards = 13/52
\(\mbox{P(red)}\) = number of red cards divided by the total number of cards = 26/52
\(\mbox{P(diamond|red)} = \frac{13/52}{26/52} = 13/26 = 0.5\)
which makes sense: 50% of the red cards are diamonds
Example:
Suppose you draw a card from a deck of 52 cards and it’s red.
What is the probability that it is a queen ?
\(\mbox{P(queen|red)}=\frac{\mbox{P(queen}\, \cap\, \mbox{red)}}{\mbox{P(red)}} \)
\(\mbox{P(queen}\, \cap\, \mbox{red)}\) = number of red queens divided by the total number of cards = 2 / 52
\(\mbox{P(red)}\) = number of red cards divided by the total number of cards = 26/52
\(\mbox{P(queen|red)}= \frac{2/52}{26/52} = 1/13\)
which makes sense: only 2 cards are queen out of the 26 red cards.
Example:
Suppose you draw a card from a deck of 52 cards and it’s red.
What is the probability that it is a queen of diamonds ?
\(\mbox{P(queen of diamonds|red)=}\frac{\mbox{P(queen of diamonds}\, \cap\, \mbox{red)}}{\mbox{P(red)}} \)
\(\mbox{P(queen of diamonds}\, \cap\, \mbox{red)}\) = number of queens of diamonds divided by the total number of cards = 1 / 52
\(\mbox{P(red)}\) = number of red cards divided by the total number of cards = 26/52
\(\mbox{P(queen|red)}= \frac{1/52}{26/52} = 1/26\)
which makes sense: only 1 cards are queen of diamonds out of the 26 red cards.
Bayes’ Theorem#
The Bayes’ theorem formalize the relation between the conditional probability P(A|B) and P(B|A):
It can be proven in one line by writing \(P(A \cap B)\) in two different ways:
\(P(A\, \cap\, B)= P(A|B) \cdot P(B) = P(B|A) \cdot P(A) = P(B\, \cap\, A)\)
and hence
\(P(A|B)=\frac{P(B|A)\cdot P(A)}{P(B)}.\)
To fix some nomenclature, let’s use a specific example where A is a theory we are testing and B is a given set of data.
P(data | theory) = “likelihood”; how likely is to measure the given set of data assuming that the theory is correct
P(theory | data) = “posterior probability”; it’s what you are interested in ! the probability that the theory is correct given the measured data
P(theory) = “prior probability”; the probability we assign to the theory to be correct based on all our knowledge before collecting the givenset of data. Typically information coming from previous experiments
P(data) = “evidence”; it’s a normalization factor: the posterior must be normalised to 1
The theorem states that the probability that A happens given B is equal to the probability that B happens given A (note that A and B are inverted) times your prior knowledge about A and divided by a normalization factor P(B). The normalization P(B), the probability for B to happen given that A or not-A happens, in all practical cases is expresses as: \(P(B) = P(B|A)P(A)+P(B|\mbox{not-A})P(\mbox{not-A})\).
Let’s take a concrete example to understand how the Bayes theorem works:
Example:
Consider a topic coming from virology. We assume that 0.1% of all swans of a certain colony are infected by an influenza virus. A specially developed test for influenza shall, in case of an infected bird, have a detection efficiency of 98%. Unfortunately, the probability of error (false positive) is 3%, which means that the test indicates an infection in 3% of all cases where the bird is not infected.
We ask now for the probability \(P\) that, after having had a positive test, a swan is actually infected by the influenza virus.
According to the given information, we have:
\(P({\rm influenza})=0.001\) (0.1% of all swans are infected)
\(P({\rm non-influenza})=1-0.001=0.999\).
The probabilities for the test response are:
\(P(+|{\rm influenza})=0.98\) and
\(P(-|{\rm influenza})=1-0.98=0.02\).
Where \(P(+|{\rm influenza})\) (\(P(-|{\rm influenza})\)) denote the positive (negative) response under the condition that the swan is actually infected.
Furthermore, the probability of a wrong result of the test is given by
\(P(+|{\rm non-influenza})=0.03\) and
\(P(-|{\rm non-influenza})=1-0.03=0.97\).
Therefore, the probability \(P({\rm influenza}|+)\) that a swan is infected, given the test was positive, is
This means that an infection is present in only 3% of all cases in which the test was positive!
One way to look at it: a test with a false positive rate of 3% means that every 1000 people tested 30 will be positive, while the number of sick people in a population of 1000 should be only 1. You are among the 30 tested positive. You are comparing 1 against 30.
Subjective probability or the Bayesian interpretation#
In Bayesian inference the probability is interpreted as a subjective “degree of belief” which can be modified by observations (more data). This is the strength of the Bayesian theorem: it provides a quantitative way to update the initial knowledge (prior belief) about a proposition when new data becomes available. Try to compute as an exercise how the \(P({\rm influenza}|+)\) of the previous example changes if you get two consecutive positive tests (see the interactive-nb ).
Going back to the case where we considered A as a theory that we want to test, and B a given set of data, we have: P(theory) the probability (“belief”) that a theory is correct before doing the experiment; P(data\(|\)theory) is the probability of getting the given set of data if the theory is true; P(data) is our normalization factor, and P (theory \(|\) data) is our belief in the theory after having obtained the result.
It’s important to notice the inversion of the logic: for \(P(\mbox{theory}|\mbox{data})\) you have collected the data and you are evaluating the probability of the theory to be right; for \(P(\mbox{data}|\mbox{theory})\) you are estimating the probability to obtain such a data distribution given a certain theory.
The fundamental difference between the frequentist approach and the Bayesian approach relies in the interpretation. The frequentist’s probability is interpreted as a State of Nature, whereas the Bayesian probability is a State of Knowledge introducing inevitably some subjectivity.
Example:
What is the probability that Nature is supersymmetric ? This question has no meaning in a frequentist inference (either it supersymmetric or it is not), but you can compute a degree of belief using the bayesian inference to compute the posterior probability, given the information you have.
The probability of an event \(P(E)\) depends on the information which is accessible to the observer. The function \(P(E)\) is therefore not purely an intrinsic function of the event, it rather depends on the knowledge and information possessed by the observer.
Unfortunately there is no a priori way to assign the “prior” assumption \(P(A)\): the assignment of the prior probability is subjective. The usual prescription is to assume complete ignorance about the prior P(A) and take all values of A as equiprobable, but there are objections to this approach:
if we are completely ignorant about P(A), how do we know it is a constant?
a different choice of P(A) would give a different P(A\(|\)B)
if we are ignorant about P(A), we are also ignorant about P(\(A^2\)) or P(1/A), etc… taking any of these (P(\(A^2\)) or P(1/A), etc…) as constant would imply a different P(A), giving a different posterior probability.
Another approach consists in developing a prior that is invariant under a change of coordinates in the parameter (or parameter space). This can be done by constructing a distribution for the prior that is proportional to the square root of the determinant of the Fisher Information. This approach goes under the name of Jeffrey’s priors [Jef48].
The distinction between the frequentist and Bayesian approaches to statistical inference reaches its climax when addressing the problem of setting confidence/credible intervals in Sec. Confidence Intervals.
The following is an example to give an idea of the problem.
Example:
Let’s take the measurement of the mass of the electron as an example to understand the difference between the frequentist and Bayesian interpretation of confidence intervals. You measure the mass of the electron to be \(520 \pm 10~keV/c^2\), i.e. you measured \(520~keV/c^2\) with an apparatus with a resolution of \(10~keV/c^2\). It is tempting to conclude that “the mass of the electron is between 510 and 530 \(keV/c^2\) with 68% probability”. This is not the frequentist’s meaning of probability. In the frequentist interpretation, the statement that the electron has a certain mass with a certain probability is nonsense. The electron has a definite mass, the problem is that we do not know what the value is. It sounds much more like a Bayesian statement: with a resolution, or “error”, of \(\sigma = 10~keV/c^2\), the probability that we will measure a mass m when the true value is \(m_e\) is
\(P(m | m_e) \propto e^{-(m - m_e)^2/2\sigma^2}\)
this is the likelihood term. Then by Bayes’ theorem, the probability that the true mass has the value \(m_e\) after we have measured a value m is
\(P(m_e | m) = \frac{P(m | m_e)P_{prior}(m_e)}{P(m)}\)
\(\propto P (m | m_e) \;\; \mbox{assuming} \;\;\;P_{prior}(m_e) = const\)
\(\propto e^{-(m-m_e)^2/2\sigma^2}\)
What we typically state is that “the 68% credible interval for the mass of the electron is between 510 and \(530~keV/c^2\). Note the use of “credible level” instead of “probability”.
This and other subtleties will be discussed further when discussing confidence intervals.
A more general case is when, instead of having only two possible cases, e.g. A or not A (the theory is either correct or wrong), you have \(n\) mutually exclusive classes \({A_i}, i=1..n\). In this case the theorem generalizes to:
Another common case is to have a continuous pdf.
Define: \(f(x,y) dx dy\) as the joint probability to observe x in \([x, x+dx]\) and y in \([y, y+dy]\) (that in case of independent variables the pdf factorizes to f(x,y)=f(x)f(y)).
Then the Bayes theorem can be written as:
where \(\int f(x,y)dx\) and \(\int f(x,y)dy\) are the marginalized pdf on z and y (see below in this chapter).
Probability density function#
We define as random variable any function of the data. The event space is the set of all possible values of a random variable. A random variable which can take any value between two arbitrarily given points in the event space is called a continuous variable; conversely, if the variable can only take certain values it is called a discrete variable. In the same manner, data described by discrete or continuous variables are called discrete data or continuous data respectively.
The distribution \(f(x)\) of a continuous random variable \(x\) is called probability density function (p.d.f.). \(f(x')dx'\) is the probability to find \(x\) in the interval between \(x'\) and \(x'+dx'\) and it is normalized \(\int_{-\infty}^{+\infty}f(x')dx'=1\) (the probability to find \(x\) anywhere in its event space is 1). Note that \(f(x)\) is not a probability but \(f(x)dx\) is.
In case of a discrete random variable \(x\) its distribution f(x) is called
probability mass function (p.m.f.) (or frequency distribution).
\(f(x_i)\) is the probability to obtain the values \(x_i\).
The p.m.f. is normalized \(\sum_0^n f(x_i)=1\), n can be \(\infty\)(the probability to find \(x\)
anywhere in its event space is 1).
In the following we will often call probability density function (p.d.f.) both the continuous and the discrete distributions.
Cumulative distribution function#
Let \(x\) be a one-dimensional continuous random variable distributed according to \(f(x)\). The cumulative distribution function (cdf) \(F(x')\) gives the probability that the random variable \(x\) will be found to have a value less than or equal to \(x'\):
It follows trivially (with some abuse of notation) that \(F(-\infty)=0\) and \(F(+\infty)=1\). The function \(F\) is a monotonic (but not necessarily strictly monotonic) rising function of \(x\).
The probability density function \(f(x)\) is then (by the fundamental theorem of calculus) \(f(x)=dF(x)/dx\).
The function \(F\) is dimensionless (and can be read as a probability) whereas the function \(f\) has dimension \(1/x\). The probability to observe the random variable \(x\) between two values \(x_1\) and \(x_2\) can be written in terms of the cdf as:
The concept of cumulative can be trivially extended to the discrete case.
The following is an example to show what is the cumulative of a pdf (chosen to be a gaussian - see next chapter for more details on the gaussian pdf).
Quantiles#
Quantiles are values taken from the inverse of the cdf of a random variable. When they are taken at regular intervals they get special names. If the set of data is split into:
two equally sized parts, then the value in the middle is the median.
four equally sized parts, then the four values are called quartiles Q1, Q2, Q3 and Q4. The value of Q2 coincides to the median.
ten parts we call them deciles
hundred parts we call them percentile.
The quantiles allow to describe any data distribution without knowing what is its underlying pdf. For example, when a baby is born the pediatrician will compare her/his weight or height with respect to a reference population of babies of the same age, in terms of percentiles. When a baby is in the 20-th weight percentile, it means that 20% of the babies in the reference sample will be lighter.
The following is an example of deciles on a gaussian distribution.
['0.0', '0.1', '0.2', '0.3', '0.4', '0.5', '0.6', '0.7', '0.8', '0.9', '1.0']
['-inf', '-1.282', '-0.842', '-0.524', '-0.253', '0.000', '0.253', '0.524', '0.842', '1.282', 'inf']
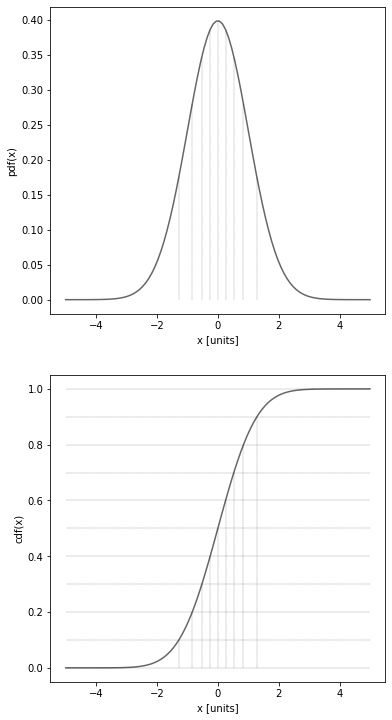
Mean, Median and Mode#
The arithmetic mean \(\bar{x}\) (or simply mean value) of a set of \(N\) numbers \(X_{i}\) is defined as:
\(\bar{x}=\frac{1}{N}\sum_{i=1}^N X_i\)
The mean of a function of \(x\), (\(\bar{f}\)) can be calculated analogously:
\(\bar{f}=\frac{1}{N}\sum_{i=1}^N f(X_i).\)
If the \(N\) data points are classified in \(m\) intervals (i.e. bins of a histogram), and if \(n_{i}\) stands for the number of entries in the interval (bin) \(i\), then:
\(\bar{x}=\frac{1}{N}\sum_{i=1}^{m}n_iX_i.\)
The median of a random variable \(x\) divides a frequency distribution into two equally sized halves:
\(\int_{-\infty}^{x_{median}}f(x')dx'=\int_{x_{median}}^{+\infty}f(x')dx'=0.5.\)
The mode or most probable value corresponds to the value of \(x\) where the probability density \(f(x)\) has a maximum. The mode is not necessarily unique: if a distribution has two maxima, we call it bimodal, if it has several maxima, we call it multimodal.
A rough relation between mode, median and mean (true for unimodal and “not very skewed” distributions) is given by
\(\mbox{ Mean - Mode}=3\times\mbox{ (Mean - Median)}.\)
So by knowing two out of the three, the third one can be estimated easily by this formula.
The weighted mean is typically used to combine measurements with different resolutions. Given a dataset {Xi} i=1..N and their (event by event) uncertainties \({\sigma_i}\) i=1..N, the weighted mean is defined as:
For the case of measurements with different resolutions we will use as weight \(w_i = 1/\sigma^2_i\).
We will see later how to also assign weights to events (i.e. instead of counting events - each event counting one - we will assign to each event a continuous weight).
import numpy as np
mu,sigma = 0,5
X = np.random.normal(mu, sigma, 11)
print ("array = ", X)
print ("size of the array = ", np.size(X))
array = [ 1.30262694 0.65958626 6.16758332 -2.42206684 3.57845248 2.96816762
9.57362627 2.74716791 1.43169306 -0.39644808 -0.95894937]
size of the array = 11
#compute the mean
sum = 0
for x in X:
sum += x
print ("mean = ", sum/np.size(X))
# or using the numpy mean function
print ("mean = ", np.mean(X))
mean = 2.2410399590125496
mean = 2.2410399590125496
#Compute the median
np.sort(X)
print ("sorted array = ", X)
np.median(X)
sorted array = [ 1.30262694 0.65958626 6.16758332 -2.42206684 3.57845248 2.96816762
9.57362627 2.74716791 1.43169306 -0.39644808 -0.95894937]
1.431693058303253
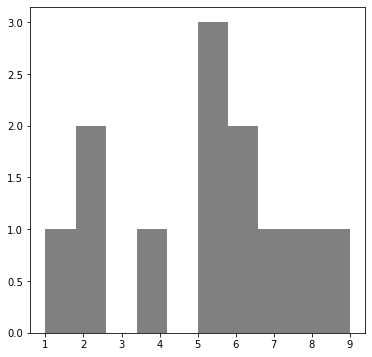
#Compute the mode of this array:
X = [ 1,2,2,4,5,5,5,6,6,7,8,9]
from scipy.stats import mode
# this will give you back the mode and the number of times it appears
print ("mode", mode(X))
mode ModeResult(mode=array([5]), count=array([3]))
# plot the distribution to see visually the mode
import matplotlib.pyplot as plt
%matplotlib inline
plt.figure(figsize=[6,6])
n, bins, patches = plt.hist(X, facecolor='grey')
plt.show()
The geometric mean \(\mu_g\) is defined as:
\(\mu_g = \sqrt[N]{x1\cdot x2\cdot \dots \cdot x_N}.\)
It is used to characterize the mean of a geometric sequence \((a, ar, ar^2, ar^3, ...)\). The geometric interpretation of the geometric mean of two numbers, a and b, is the length of one side of a square whose area is equal to the area of a rectangle with sides of lengths a and b.
Example:
A population of bacteria grows from 2000 to 9000 in 3 days.
What is the daily grow (assuming a constant rate r) ?
\(1^{st}\) day: \(n_1\) = 2000 + 2000 r
\(2^{nd}\) day: \(n_2\) = n1 + n1 r = 2000 \((1+r)^2\)
\(3^{rd}\) day: \(n_3\) = n2 + n2 r = 2000 \((1+r)^3\) = 9000
\(\Rightarrow 1+r = \sqrt[3]{4.5} \Rightarrow r = 65.1\%\)
The function
\(f(x) = a \cdot (1+f)^x\)
is called geometrical or exponential growth when \(x\) is discrete or continuous respectively. It covers a particularly important role in finance where it describes the compound interest (see the interactive notebook in this section).
The harmonic mean \(H\) is defined as:
\(\frac{1}{H}=\frac{1}{N}\sum_{i} \frac{1}{X_{i}}.\)
It is characterize the mean value of a harmonic sequence
\(\frac{1}{a}\;, \;\frac{1}{a+d}\;, \;\frac{1}{a+2d}\;,...\;,\; \frac{1}{a+kd}\;,...\)
Example:
A car travels at 80 km/h for the half of the trip and 100 km/h for the second half. What’s his average speed? 2/(1/80+1/100) = 89 km/h (averaging over periods of time not distances)
Expectation value#
The expectation value of a random variable \(x\) (or first moment) is defined as:
\(<x>=\int_{-\infty}^{\infty} x' f(x') dx'\)
and for discrete variables \(r\) as:
\(<r>=\sum r_i P(r_i).\)
where \(f(x)dx\) is the probability that the value x is found to be in the interval \((x, x+dx)\) and in the discrete case \(P(r_i)\) is the probability that the value \(r_i\) occurs.
The expectation value reduces to the arithmetic mean when the probability for any value to occur (\(f(x)\) in the continuous case or \(P(r)\) in the discrete case) is constant. Take e.g. the discrete case and set the probability for any event \(r_i\) \((i = 1,...,N )\) to occurr to be the same. Because \(P(r_i)\) is normalized \(\sum_{i=1}^N P(r_i) = 1\) then for each \(i\), \(P(r_i) = 1/N\):
\(< r > = \sum r_i P(r_i) = \frac{1}{N}\sum r_i\)
More generally, the expectation value for any symmetric probability distribution will coincide with the arithmetic mean. In case of asymmetric distributions, the expectation value will be pulled towards the side of the largest tail (more details on this when we will see some examples of probability distibution functions).
The expectation value of a function \(h(x)\) is defined by \(<h>=\int h(x')f(x')dx'\).
The expectation value is a linear operator, i.e.
\(<a\cdot g(x)+b\cdot h(x)> = a <g(x)>+\,b <h(x)>,\)
but in general \(<fg>\ne<f><g>\). The equality is true only if \(f\) and \(g\) are independent.
Example:
In quantum mechanics, to compute the expectation value of A, the eigenvalues (outcomes of a measurement) are weighted on their probability to occur: \(\langle A \rangle_\psi = \sum_j a_j |\langle\psi|\phi_j\rangle|^2\)
Note that the expectation value need not be one of the possible elements !
For instance: rolling a die \(E[x] = 1\cdot1/6 + 2\cdot1/6 + 3\cdot1/6 + 4\cdot1/6 + 5\cdot1/6 + 6\cdot1/6 = 3.5\)
Variance and Standard Deviation#
The expectation values of \(x^{n}\) and of \((x-<x>)^{n}\) are called the \(n^{th}\) algebraic moment \(\mu_{n}\) and the \(n^{th}\) central moment \(\mu'_{n}\), respectively. Central refers to the fact that the expectation value of x is subtracted from each value of x (which in case of a symmetric distribution effectively centers it at zero).
The first algebraic moment \(\mu_{1}\) is equal to the expectation value \(<x>\) and it is usually just called \(\mu\). The first central moment is zero by definition.
The second central moment is a measure of the width of a probability distribution and it is called variance \(V(x)\). Its square root is called the standard deviation \(\sigma\):
\(\begin{aligned} V(x) &=& <(x-<x>)^2> = <x^2 + <x>^2 -2x<x> >= \\ &=& <x^2> + <x>^2 - 2<x><x> = <x^2>-<x>^2 \end{aligned}\)
where we just used the linearity of the expectation value.
We will see when discussing the characteristic function that any pdf is uniquely described by its moments (see Characteristic function)
The variance is not a linear operator:
i.e. if you shift a random variable the variance of its distribution will not change, while if you scale it by a constant b, the variance will increase by \(b^2\).
It is important to notice that quantities like the variance or the standard deviation are defined using expectation values, and they can only be determined if the “true” underlying probability density of the sampling distribution is known. When analysing data we need to distinguish the distribution of the collected data, the (known) sampling distribution, from the (unknown) parent distribution that we are effectively sampling with our measurements. One of the goals of data analysis (called parameter estimation) is to estimate the parameters of the parent distribution from the properties of the collected data sample.
When the the mean \(<x>\) of the parent distribution is not known, we define the sample variance, commonly called \(s^{2}\), as:
\(\begin{aligned} \label{samplevariance} s^2&=& \frac{1}{N-1}\sum_i(x_i-\bar{x})^2 \\\end{aligned}\).
To compute this expression, one has to loop on the data a first time to compute the sample mean, and then a second time to compute the sample variance. A little algebra, transforms the previous expression into
\(\begin{aligned} s^2 &=& \frac{1}{N-1}\left(\sum_i x_i^2-\frac{1}{N}\left(\sum_i x_i\right)^2\right) \end{aligned}\)
that can be computed by looping only once on the events. This is particularly useful when the number of data points is huge.
The value of \(s^{2}\) can be understood as the best estimate of the “true” variance of the parent distribution. The origin of the factor \(\frac{1}{N-1}\) instead of the usual \(\frac{1}{N}\) will become clear when we will discuss the theory of estimators, but naively you can interpret it as the variance becomes meaningless when you only have one point (N=1).
Example:
The following table collects some of the quantities defined above, for the Maxwell distribution. The probability density for the magnitude of the velocity \(v\) of molecules in an ideal gas at temperature \(T\) is given by:
Here, \(m\) is the mass of the molecule and \(k_{B}\) is the Boltzmann constant.
Quantity |
Value |
|---|---|
Mode (most probable value) \(v_m\) |
\((2kT/m)^{1/2}\) |
Mean \(<v>\) |
\((8kT/\pi m)^{1/2}\) |
Median |
\(v_{median}= 1.098\cdot v_m\) |
RMS-velocity \(v_{rms}\) |
\((3kT/m)^{1/2}\) |
Full Width at Half Maximum#
Another way to characterize the spread of the data is to compute the Full Width at Half Maximum (FWHM). Given a distribution P(x), the FWHM can be computed as the difference between the two values of x at which P(x) is equal to half of its maximum. For a gaussian distribution the relation between FWHM and the standard deviation is:
\(\mbox{FWHM} = 2\sqrt{2\ln2}\sigma \sim 2.355\sigma\)
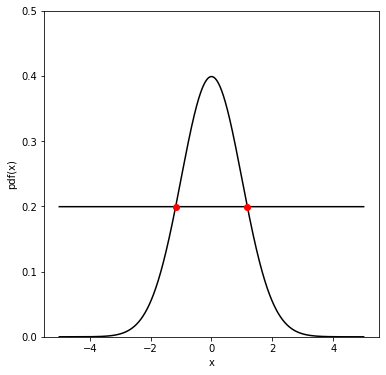
Half Maximum = 0.19947114020071635
Intersections: [-1.178 1.177]
FWHM = 2.3550000000007865
Higher Moments#
The third moment is called skewness \(\gamma_1\) and it is often defined as
\(\gamma_1=\mu'_3/\sigma^3=\frac{1}{\sigma^3}<(x-<x>)^3>= \frac{1}{\sigma^3}(<x^3>-3<x><x^2>+2<x>^3).\)
The quantity \(\gamma_1\) is dimensionless and characterizes the skew. It is zero for symmetric distributions, and positive(negative) for asymmetric distributions with a tail to the right(left).
Another definition of skewness often used is the Pearson’s skew given by \((mean-mode)/\sigma\).

The kurtosis \(\gamma_2\) is defined as \(\gamma_{2}=\mu'_4/\sigma^4-3\), which is a (dimensionless) measure of how the distribution behaves in the tails compared to its maximum. The factor \(-3\) is subtracted to obtain a kurtosis of zero for a Gaussian distribution. A positive \(\gamma_{2}\) means that the distribution has larger tails than a Gaussian distribution with the same values for mean and variance.
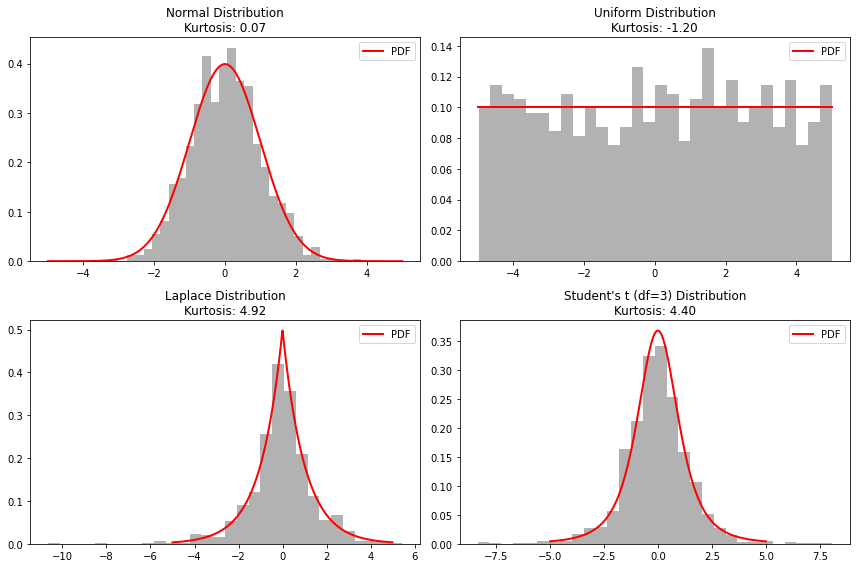
Here are some useful scipy functions to compute moments:
import numpy as np
mu,sigma = 0,5
X = np.random.normal(mu, sigma, 101)
#print (X)
from scipy.stats import moment
for i in range(1,5):
print (str(i)+"-th moment", moment(X, moment=i))
1-th moment 0.0
2-th moment 25.292978429991994
3-th moment -5.629257900739212
4-th moment 1842.355169810612
from scipy.stats import skew
skew(X)
# left tail
Xleft = np.array([0,1,1,1,3,3,3,3,3,4])
print ("left", skew(Xleft))
# right tail
Xright = np.array([0,1,1,1,3,4,5,6])
print ("right", skew(Xright))
left -0.3818440590736698
right 0.337575590140799
from scipy.stats import kurtosis
kurtosis(X)
-0.1201265099719997
Moment generating function#
A way to compute all moments of a pdf is to use the moment generating function, defined as:
The integral is only defined in a neighbour of \(\zeta=0\). If you expand the exponential you get:
With this all moments can be computed from the derivatives:
Example:
Take the exponential distribution:
The moment generating function is:
from which you get:
Useful Inequalities#
Two useful inequalities can be used to estimate the upper limits
probabilities if the underlying distribution is not known. Both
inequalities are given without proof.
Let \(x\) be a positive random variable. Then it holds:
\(P(x\geq a) \leq \frac{<x>}{a}.\)
This inequality provides an upper limit for the probability of random events located in the tails of the distribution.
Let \(x\) be a positive random variable. Then it holds:
\(P(\,|~x~-<x>|\geq k)\leq \frac{\sigma^2}{k^2}\)
So for example the probability for a result to deviate for more than three standard deviations from the expectation value, is always smaller than 1/9, independent of the underlying probability distribution. The inequality is true in general, but it gives quite a weak limit (for a Gaussian distribution, the probability to lie outside three standard deviations is about 0.0027, see next chapter). It is nevertheless useful for qualitative considerations, if nothing at all is known about the underlying distribution.
Characteristic Function#
The characteristic function \(\Phi(t)\) is defined as the expectation value of \(e^{itx}\) for a p.d.f. \(f(x)\):
i.e \(\Phi(t)\) is the Fourier integral of f(x). The characteristic function completely determines the p.d.f., since by inverting the Fourier transformation we regain \(f(x)\):
The characteristic function as well as its first and second derivative are readily calculated for the special case where \(t=0\):
What do we need characteristic functions for? They may be useful when performing calculations with probability densities, for example if the convolution of two probability densities \(f_{1}\) and \(f_{2}\) for two random variables \(x_{1}\) and \(x_{2}\) should be calculated. A convolution of \(f_{1}\) and \(f_{2}\) yields a new probability density \(g(y)\), according to which the sum of the random variable \(y = x_{1} + x_{2}\) is distributed as:
The convolution integral can now be transformed with the help of the characteristic functions:
In words: the characteristic function (Fourier transform) of the convolution of two variables is obtained by the product of their characteristic functions. For example it can be easily shown that the convolution of two Gaussian distributions with \(\mu_{1,2}\) and \(\sigma_{1,2}\) is again a Gaussian distribution with \(\mu = \mu_{1} + \mu_{2}\) and \(\sigma^{2} = \sigma_{1}^{2} + \sigma_{2}^{2}\). Furthermore, the convolution of two Poisson distributions is again a Poisson distribution. The characteristic functions of some probability densities are:
Distribution |
Characteristic Function |
|---|---|
Binomial |
\(\Phi(t)=(pe^{it}+q)^n\) |
Poisson |
\(\Phi(t)=e^{\lambda(e^{it}-1)}\) |
Gauss |
\(\Phi(t)=e^{i\mu t-t^2\sigma^2/2}\) |
\(\chi^2\) |
\(\Phi(t)=(1-2it)^{-n/2}\) |
Uniform (from a to b) |
\(\Phi(t)=(e^{ibt}-e^{iat})/(b-a)^{it}\) |
Breit-Wigner |
$\Phi(t)=e^{-iE_0t-(\Gamma/2) |
Gamma |
\(\Phi(t)=(1-it/\mu)^{-\alpha}\) |
More than one dimension#
When doing measurements we are often performing a sampling of a multi-dimensional pdf. For example in the case of a 2D pdf, the probability to observe \(X\) in \([x, x+dx]\) and \(Y\) in \([y, y+dy]\) is:
\(\begin{aligned} P(x< X < x+dx, y < Y < y+dy) &=& f(x,y)dx dy\\ P(a< X < b, c < Y < d) &=& \int_a^b dx \int_c^d dy f(x,y)\\\end{aligned}\)
For multi-dimensional pdfs we can define the concept of marginal and conditional pdf. To get the idea let’s take a 2D example:
Marginal pdf: it’s the pdf describing \(x\) independently of the value of \(y\); the 2D probability can be “marginalised / projected” by integrating over one variable
\(\begin{aligned} f_1(x) &=& \int_{-\infty}^{+\infty}f(x,y)dy \\ f_2(y) &=& \int_{-\infty}^{+\infty}f(x,y)dx \\ \end{aligned}\)
Conditional pdf: it’s the pdf of \(x\) for a fixed value of \(y\):
\(\begin{equation} P(X|Y) = \frac{f(X|Y=y)}{\int_{-\infty}^{+\infty}f(x,y)dx} = \frac{f(X|Y=y)}{f_2(y)} \end{equation}\)
In plain english: the marginal pdf ignores the values of the other variable(s), the conditional pdf fix the value of the other variable(s).
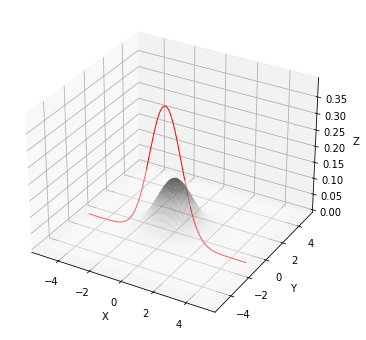
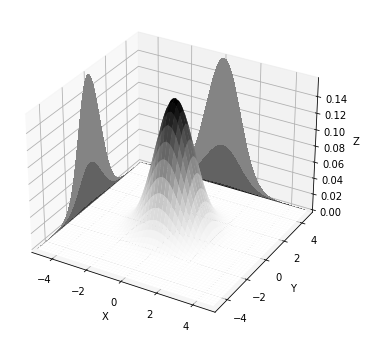
The multivariate gaussian conditioned at y=-1 P(X|Y=-1) (plot on the left), is the slice at y=-1 (i.e. a 1D gaussian) normalized to 1.
Transformation of variables#
Let’s consider a 2-dimensional event space as an example (easily generalizable to the N-dimensional case) and call the two random variables \((x,y)\). How does the pdf \(f(x,y)\) transforms under a change of variable to \((X,Y)\)?
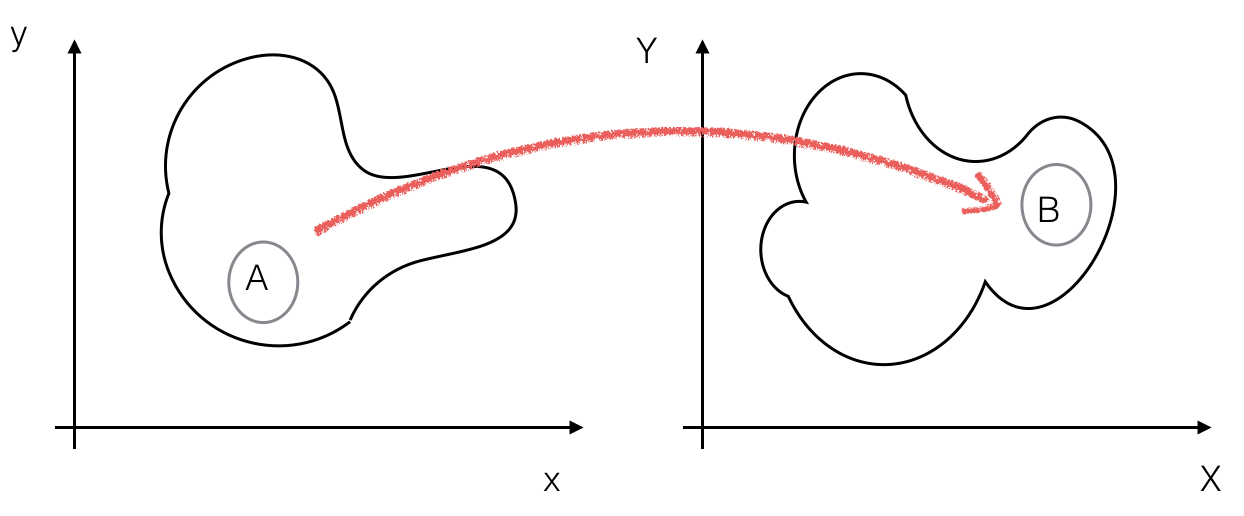
Consider a small interval \(A\) around a point \((x,y)\) that we will transform to a small interval \(B\) around the point \((X,Y)\) such that \(P(A)=P(B)\):
Assume that the transformation
is bijective so that the inverse exist (together with the first derivative):
Then
where J is the Jacobian determinant:
So the p.d.f. in (X,Y) is the p.d.f. in (x,y) times the Jacobian:
The error propagation that we will encounter later, can be viewed as a change of variables (see also PFG:Propagation of errors )
Covariance and Correlation#
Let \(f(x_1,x_2) dx_1 dx_2\) be the joint probability to observe \(x_1\in [x_1,x_1+dx_1]\) and \(x_2\in [x_2, x_2+dx_2]\). The two variables \(x_1\) and \(x_2\) are uncorrelated if and only if they fulfill the following relation:
\(f(x_1,x_2)=f(x_1)\cdot f(x_2).\)
If the above condition is not fulfilled, then the variables are correlated.
The covariance \(cov(x_{1},x_{2})\) between two variables is defined as
\(cov(x_1,x_2)=<(x_1-<x_1>)\cdot (x_2-<x_2>)>=<x_1x_2>-<x_1><x_2>.\)
If two variables are uncorrelated then \(<x_1x_2>=<x_1><x_2>\) and so the
covariance is zero.
Knowing the covariance between two variables, we can write the general
expression of the variance of their sum:
\(V(x_1+x_2)=V(x_1)+V(x_2)+2\cdot cov(x_1,x_2).\)
Some more properties of the covariance are: (\(a\in \mathbb{R}\))
\(cov(x,a) = 0\)
\(cov(x,x) = V(x)\)
\(cov(x,y) = cov(y,x)\)
\(cov(ax,by) = ab~cov(x,y)\)
\(cov(x+a,y+b) = cov(x,y)\) is translation invariant (shift origin)
\(cov(x,y)\) has units !
The correlation coefficient between \(x_{1}\) and \(x_{2}\) is defined as:
The correlation coefficient is the covariance normalized by the square root of the product of the variances, and it is bound between -1 and +1.
If two variables are uncorrelated, given that their covariance is zero, also \(\rho_{x_1 x_2}=0\). The inverse is not necessarily true, as illustrated by the examples in Fig. 1.
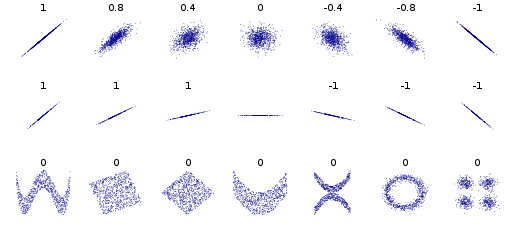
Fig. 1 Several sets of (x, y) points, with the Pearson correlation coefficient of x and y for each set. wikipedia#
Being uncorrelated is a weaker condition than being independent.
Note in particular the second raw where the correlation coefficient is not defined for the horizontal line because one of the variables has null variance; and the third raw, where the correlation coefficient is always zero.
Given a sample of size \(n\) (\((x_{1},y_{1}),(x_{2},y_{2}),\ldots, (x_{n},y_{n})\)), the sample covariance or empirical covariance \(s_{xy}\), which is the best estimate for the (true) covariance \(s_{xy}\) is given by:
and the empirical correlation \(r_{xy}\) also called Pearson-correlation-coefficient gives the best estimate for the (true) correlation coefficient \(\rho_{xy}\):
Here, the sample variances are labeled with \(s_{x}\) and \(s_{y}\), respectively.
See also later the concepts of mutual information, cross entropy, Kullback-Leibler divergence and Wasserstein metrix.
A word of caution: “correlation is not causation”. The fact that one can find a correlation between two observables does not necessarily means that there is a causality relation between the two (see Fig. 2)
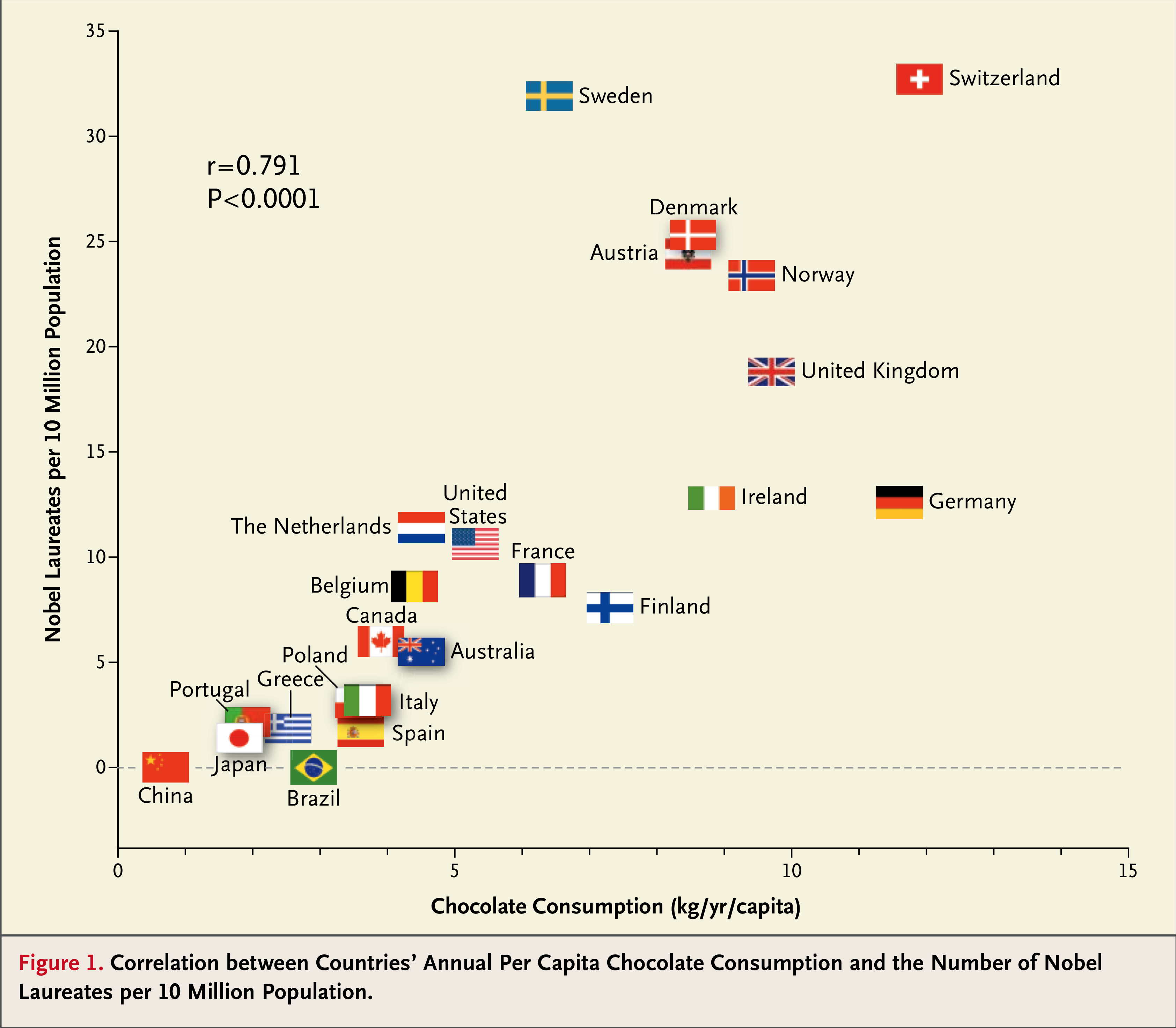
Fig. 2 “Chocolate consumption, cognitive function, and Nobel laureates. N. Engl. J. Med. 2012 Oct 18; 367(16):1562-4.#
References#
Most of the material of this section is taken from: